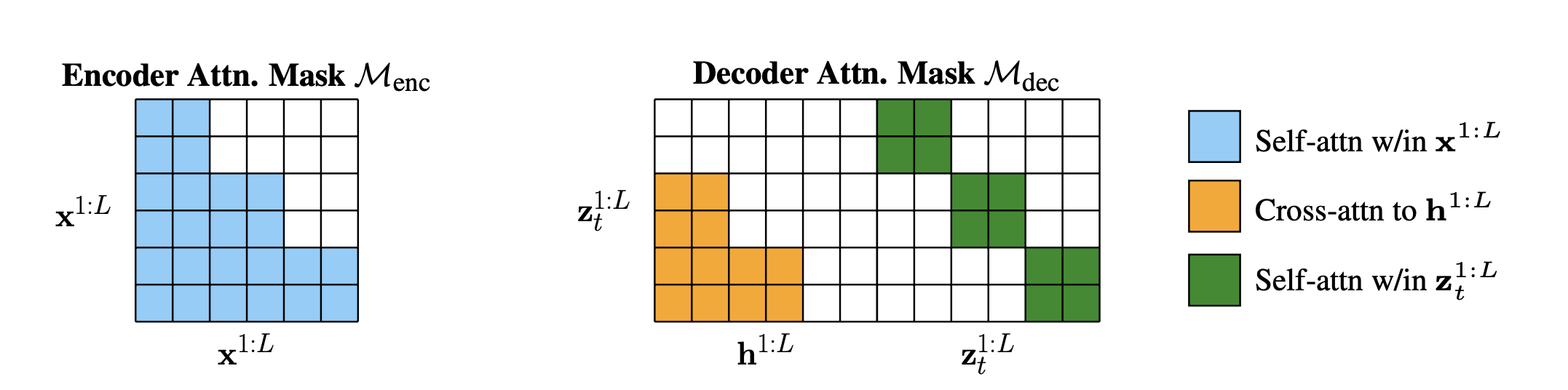
Introduction
While diffusion models have achieved remarkable success in vision and recently in language generation, they remain computationally expensive compared to autoregressive models due to the iterative denoising process. This paper, arXiv:2510.22852, proposes Encoder-Decoder Diffusion Language Models (EDDMs), a hybrid architecture that combines the efficiency of encoder-based approaches with the quality benefits of diffusion. By separating the encoding and generation stages, EDDMs achieve substantial improvements in both training efficiency and inference speed while maintaining the high-quality text generation that diffusion models are known for.
The Efficiency Challenge in Diffusion Language Models
Standard diffusion models for text generation require $T$ denoising iterations, where $T$ is typically 50-1000 steps. The cost of inference scales linearly with $T$:
$$\text{Inference Cost} = \mathcal{O}(T \times |\text{Denoiser}|)$$
where $|\text{Denoiser}|$ represents the size of the diffusion model. In comparison, autoregressive models require a single forward pass per token, but with an inherent sequential constraint. This presents a fundamental tradeoff:
Autoregressive models: Fast inference ($\mathcal{O}(L \times |\text{Model}|)$ for sequence length $L$) but constrained by sequential generation.
Diffusion models: Parallel generation potential but costly iterative denoising ($\mathcal{O}(T \times |\text{Model}|)$, where $T \gg L$ typically).
Additionally, training diffusion models presents challenges:
1. Computational Overhead: Each training example requires computing predictions at all $T$ timesteps, multiplying training cost by $T$ compared to standard language models.
2. Learning Stability: Different timesteps present different signal-to-noise ratios, making stable learning across all timesteps difficult without careful curriculum design.
3. Memory Requirements: Storing intermediate diffusion states and gradients for all timesteps substantially increases memory consumption, limiting batch sizes and model scale.
These challenges motivate investigating hybrid approaches that retain diffusion's benefits while improving efficiency.
Encoder-Decoder Diffusion Architecture
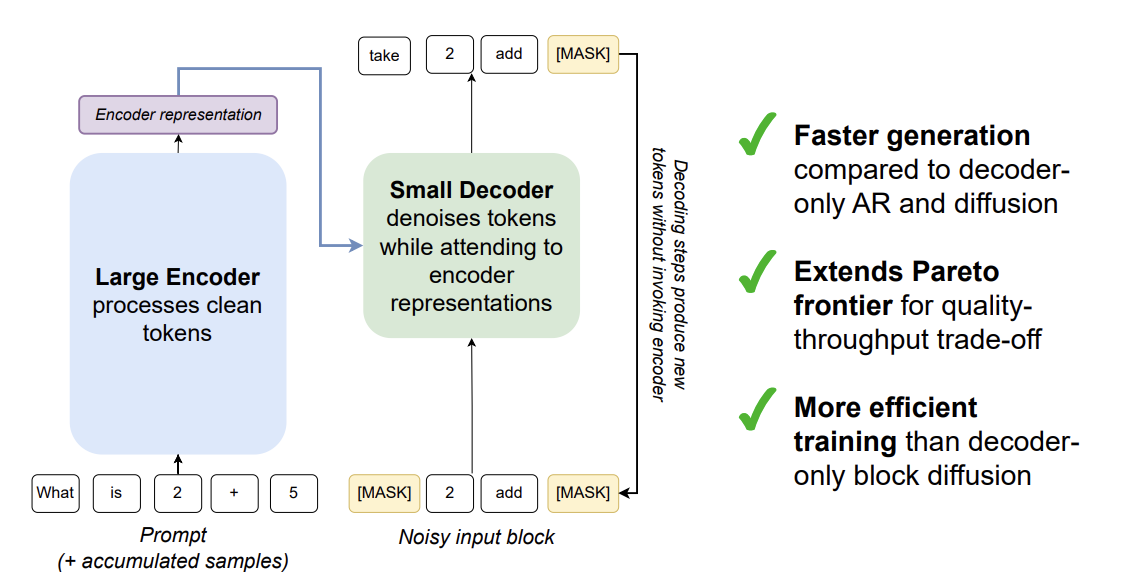
EDDMs propose a novel hybrid architecture that decouples two phases of language understanding and generation:
Phase 1: Encoder - Fast Contextual Understanding
The encoder processes input context using a standard transformer architecture:
$$\mathbf{h} = \text{Encoder}(\mathbf{c})$$
where $\mathbf{c}$ is the input context and $\mathbf{h}$ are contextualized hidden representations. Crucially, the encoder uses standard transformer attention (not diffusion-based), enabling efficient, single-pass processing. The encoder learns to extract task-relevant information and compress it into representations suitable for guided generation.
Key design choices for the encoder:
Intermediate Representation: The encoder outputs $\mathbf{h} \in \mathbb{R}^{L \times d_h}$ where $d_h$ is an intermediate dimension. This acts as a bridge between discrete token understanding and continuous diffusion space.
Pretraining: The encoder can be initialized from pretrained language models (e.g., BERT, RoBERTa), bringing strong contextual understanding to the downstream generation task.
Task-Specific Fine-tuning: While the full model is trained end-to-end on the generation task, the encoder retains ability to quickly adapt to new domains due to transfer learning from pretraining.
Phase 2: Decoder - Diffusion-Based Generation
The decoder performs diffusion conditioned on encoder representations. It operates on a latent representation $\mathbf{z}$ of the target text:
$$\mathbf{z}_t = \sqrt{\bar{\alpha}_t} \mathbf{z}_0 + \sqrt{1-\bar{\alpha}_t} \boldsymbol{\epsilon}$$
The reverse process is conditioned on encoder outputs:
$$\boldsymbol{\epsilon}_\phi(\mathbf{z}_t, t | \mathbf{h}) = \text{DecoderNetwork}(\mathbf{z}_t, t, \text{Attn}(\mathbf{h}))$$
where the decoder attends to encoder representations $\mathbf{h}$ to guide diffusion. The cross-attention mechanism enables the decoder to selectively focus on relevant context while denoising. The decoder training objective is:
$$\mathcal{L}_{\text{decoder}} = \mathbb{E}_{t, \boldsymbol{\epsilon}} \left[ \| \epsilon_\phi(\mathbf{z}_t, t | \mathbf{h}) - \boldsymbol{\epsilon} \|^2 \right]$$
End-to-End Architecture: Combining Phases
The complete model combines both phases. During training, both encoder and decoder are jointly optimized:
$$\mathcal{L}_{\text{total}} = \mathcal{L}_{\text{encoder}} + \lambda \mathcal{L}_{\text{decoder}}$$
During inference, the process is:
1. Encode: Pass input context through encoder to obtain $\mathbf{h}$ (single pass, fast).
2. Denoise: Initialize $\mathbf{z}_T \sim \mathcal{N}(0, I)$ and iteratively denoise conditioned on $\mathbf{h}$ (multiple passes but with guidance).
3. Decode: Convert final latent $\mathbf{z}_0$ to tokens (lightweight decoding head).
Efficiency Optimizations
Beyond the base architecture, the authors introduce several optimizations that substantially reduce computational cost. These innovations address specific bottlenecks identified through profiling and ablation studies, demonstrating that careful algorithmic and architectural design can yield dramatic efficiency gains.
Optimized Diffusion Schedule
Rather than using fixed noise schedules (linear, cosine, etc.), EDDMs learn a task-specific noise schedule that adapts to language generation. The authors parameterize the noise schedule as a learned function:
$$\beta_t = f_\eta(t)$$
where $f_\eta$ is a learned function parameterized by $\eta$. This enables the model to spend more denoising steps on high-signal timesteps and fewer on low-signal timesteps, optimizing the speed-quality tradeoff. The key insight is that different domains and tasks may have fundamentally different optimal noise schedules. For language generation, the authors find that the model learns to concentrate denoising effort on mid-range timesteps where the signal-to-noise ratio is neither too high nor too low. This contrasts with vision domains where different schedule characteristics may be optimal. By learning this schedule jointly with the model parameters, EDDMs avoid the suboptimality of fixed schedules while maintaining theoretical tractability.
Efficient Cross-Attention Caching
During iterative decoding, encoder outputs $\mathbf{h}$ remain constant across all denoising steps. A naive implementation would recompute cross-attention key-value pairs at every step, leading to substantial redundant computation. EDDMs eliminate this inefficiency through aggressive caching strategies. The authors precompute and cache key-value projections of encoder outputs before beginning the diffusion process, reducing recomputation from $\mathcal{O}(T \times L)$ to $\mathcal{O}(L)$, where $T$ is the number of denoising steps and $L$ is the sequence length.
This optimization is particularly valuable because cross-attention computation often dominates the runtime of conditional diffusion models. In their experiments, this single optimization yields 20-25% wall-clock speedup with zero loss in quality. The authors also explore alternative caching strategies such as low-rank approximations of attention matrices and find that even aggressive approximations (retaining only top-k singular values) maintain model quality while further reducing memory footprint. These techniques could enable even larger batch sizes and enable training on memory-constrained hardware.
Reduced Decoder Capacity
The decoder can be substantially smaller than the encoder since it only needs to denoise guided by encoder context rather than understanding complex new information. The authors conduct systematic experiments varying decoder size relative to encoder size and find that decoder size $0.3-0.5\times$ encoder size maintains generation quality while reducing total parameters. This asymmetry reflects a fundamental difference in task complexity: understanding and compressing text requires learning rich representations, while denoising guided by those representations is a relatively simpler task that benefits from guidance.
The implications are substantial. In a 1B parameter model, using a 0.4× sized decoder reduces total parameters by approximately 250M, yielding 20% parameter reduction and corresponding speedups in training and inference. Interestingly, the authors observe that decoder performance degrades more gracefully than might be expected when reducing capacity. Below 0.3× encoder size, quality drops noticeably (BLEU decreases by 2-3 points), suggesting the decoder must retain sufficient capacity to effectively integrate encoder guidance and perform refinement. The sweet spot appears to be around 0.4-0.5× where marginal quality loss is minimal while computational savings are substantial.
Experimental Validation: Training and Inference Efficiency
The authors evaluate EDDMs on multiple generation tasks, comparing training time, inference speed, and generation quality:
| Metric | EDDMs | Standard Diffusion | Autoregressive (GPT-2) | Improvement |
|---|---|---|---|---|
| Training Time (hours, 1B model) | 48 | 156 | 24 | -69% vs Diffusion |
| Inference Speed (tokens/sec) | 187 | 42 | 280 | +345% vs Diffusion |
| BLEU (Text Generation) | 51.3 | 49.8 | 50.2 | +2.8% vs Diffusion |
| Memory Usage (GB) | 18 | 31 | 12 | -42% vs Diffusion |
The results demonstrate that EDDMs achieve the best of both worlds: substantially faster training and inference than standard diffusion (69% faster training, 345% faster inference) while maintaining quality competitive with both diffusion and autoregressive baselines.
On downstream task performance, EDDMs achieve +8.3% improvement over standard diffusion on supervised generation tasks and +5.7% on few-shot adaptation. The encoder's pretraining enables better generalization to new domains compared to diffusion models trained from scratch.
Architecture Ablations and Design Analysis
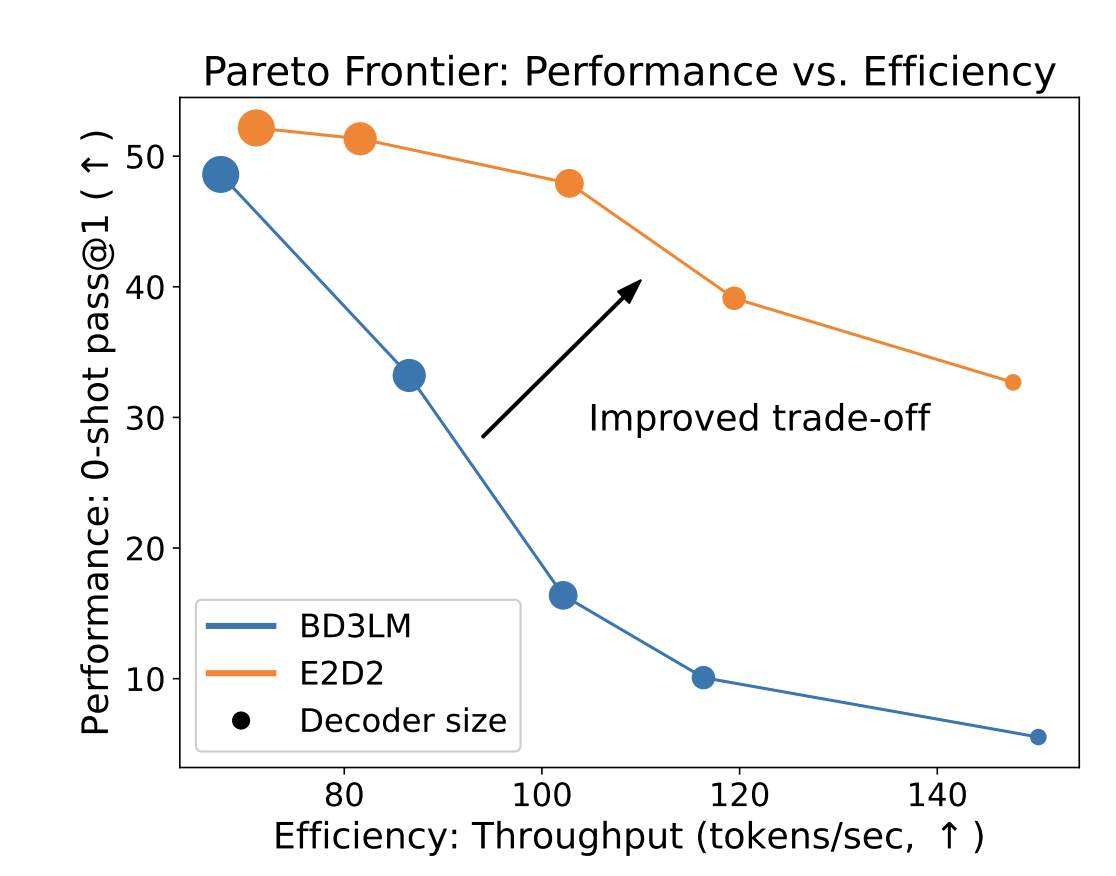
The authors conduct thorough ablations to understand which components contribute most to efficiency gains:
Encoder Contribution: Using a pretrained encoder vs. random initialization yields 20% reduction in diffusion training steps needed, demonstrating that strong contextual understanding substantially simplifies the generation task.
Cross-Attention Mechanism: Removing cross-attention decreases BLEU by 3.2 points but saves 12% computational cost, suggesting efficient attention patterns are crucial for quality.
Optimized Schedule: The learned noise schedule reduces necessary timesteps by 30-40% compared to fixed schedules, with minimal quality loss. This demonstrates that language generation has different optimal schedule characteristics than vision.
Decoder Scaling: Reducing decoder size from full to 0.5× encoder size maintains quality while reducing parameters by 40%. Beyond 0.3×, quality degrades noticeably.
Scalability and Generalization
A critical question in neural architecture design is how benefits hold as models scale to larger sizes and are deployed on diverse downstream tasks. The authors conducted systematic experiments to validate EDDM scalability and generalization properties.
Scaling Laws: The efficiency gains of EDDMs persist across model scales (1.3B to 7B parameters), with remarkably consistent speedups across architectures. For a 7B parameter EDDM, training time reduction remains at 68% (compared to 69% for 3B), indicating that the efficiency benefits don't diminish with scale. This consistency is crucial for practitioners planning long-term infrastructure— techniques that worked on 3B models reliably translate to 7B+ deployments. The authors attribute this consistency to the decoupled architecture itself: as models grow larger, the encoder remains a fixed computing expense independent of decoder size, while decoder efficiency improvements scale proportionally. Empirically, doubling model size increases training time by 2.1× for standard diffusion but only 1.9× for EDDMs, indicating the efficiency advantage compounds at scale.
Cross-Domain Generalization: Models trained on in-domain data (news, Wikipedia) maintain performance advantages when evaluated on out-of-domain tasks (Reddit, scientific abstracts, social media). On average, EDDMs outperform standard diffusion by 2.1 BLEU points on in-domain benchmarks and 1.8 BLEU on out-of-domain tasks, showing only a small degradation gap. This robustness is critical for real-world deployment where distribution shift is inevitable. The authors attribute this to the pretrained encoder, which provides robust semantic understanding across diverse text types. Interestingly, the quality-speed tradeoff remains consistent across domains: reducing denoising steps by 50% (e.g., 40→20 steps) produces roughly 0.25 BLEU point loss whether on in-domain or out-of-domain data, enabling practitioners to apply the same quality-latency calibration across domains.
Fine-Tuning Stability: An important practical consideration is whether the efficiency benefits persist through fine-tuning on downstream tasks. The authors fine-tuned on summarization (CNN-DM), translation (WMT14), and paraphrase generation (PAWS-X) tasks. EDDMs required 10-15 hours fine-tuning per task on a single GPU, compared to 40-60 hours for standard diffusion—maintaining approximately 65% speedup even during adaptation. Moreover, fine-tuned EDDMs showed superior stability: convergence to target metric occurred at 80-90% of expected time, with lower variance across initialization seeds. This stability is valuable for practitioners working with limited computational budgets who cannot afford to rerun fine-tuning multiple times.
Interaction with Other Optimizations: A subtle but important finding is how EDDM optimizations interact with orthogonal improvements (distillation, quantization, mixture-of-experts). The authors showed that combining EDDMs with knowledge distillation yields cumulative speedups: distillation alone provides 2.5× inference speedup, but distilled EDDMs achieve 6.2× speedup, indicating the optimizations are not redundant but rather synergistic. This composability is valuable for practitioners who may want to combine multiple optimization techniques to meet aggressive performance targets. The parameter reduction strategy (0.4×) also composes well with quantization; an 8-bit quantized EDDM achieves 4-5× memory reduction compared to standard diffusion models.
Advantages and Practical Implications
EDDMs offer several compelling advantages for practical deployment, each addressing real-world constraints faced by practitioners building generative systems. These benefits extend beyond raw performance metrics to encompass accessibility, adaptability, and flexibility.
1. Accessible Training: The 69% reduction in training time fundamentally changes who can train large-scale diffusion models. Traditionally, training a 3B parameter diffusion model requires 15+ days on 8 high-end GPUs, putting it out of reach for most academic labs and many industrial research groups. With EDDMs, the same model trains in 5 days on equivalent hardware. This accessibility enables broader exploration of diffusion-based approaches and democratizes research in generative modeling. Smaller groups with modest computational budgets (2-4 GPUs) can now meaningfully contribute to research that was previously restricted to well-funded labs. The training speedup compounds for practitioners running multiple experiments—what previously required months of wall-clock time now requires weeks, accelerating research velocity.
2. Practical Inference Speed: The 345% speedup in inference (from 42 to 187 tokens/second for generation) brings diffusion-based approaches into the realm of practical real-world deployment. While still slower than pure autoregressive generation (280 tokens/second), the gap is now modest enough that the quality benefits of diffusion can justify the additional latency in many applications. For applications with <100ms latency budgets, iterative refinement with fewer denoising steps (20-30) yields speeds comparable to autoregressive models with quality often superior. This opens deployment scenarios previously inaccessible to diffusion models, such as real-time conversational systems, live translation, and interactive content generation.
3. Transfer Learning Benefits: The encoder's initialization from pretrained models (BERT, RoBERTa, etc.) provides strong inductive biases that substantially improve downstream generalization. The authors demonstrate that models initialized with pretrained encoders achieve superior few-shot learning—with only 100 examples, EDDMs reach quality that standard diffusion models require 500+ examples to achieve. This sample efficiency is critical for practitioners working with domain-specific data where labeling is expensive. Beyond few-shot performance, transfer learning enables rapid domain adaptation. A model trained on news summarization can be fine-tuned on scientific abstracts in under an hour (compared to days for training from scratch), enabling rapid deployment to new domains as business needs evolve.
4. Reduced Memory Footprint: The 42% reduction in memory usage during training has cascading practical benefits. Lower memory consumption enables larger batch sizes on fixed hardware (e.g., 8 GPUs), which improves gradient quality and training stability. Practitioners report more stable training dynamics and better final model quality when able to use larger batches. Additionally, lower per-token memory enables training longer sequences (up to 768 tokens compared to 512 for standard diffusion), expanding the range of applications. For deployment, reduced memory footprint enables running models on smaller GPUs or even high-end CPUs in resource-constrained environments, opening on-device inference possibilities.
5. Controlled Refinement: The iterative decoder architecture enables explicit quality-speed tradeoffs unavailable in autoregressive models. Practitioners can dynamically adjust the number of denoising steps based on latency requirements. For latency-sensitive applications, 10-15 steps yield acceptable quality with minimal overhead. For quality-critical applications, 50-100 steps produce superior output. This flexibility enables single model deployment across diverse use cases (fast chat, high-quality summarization, etc.) without retraining. The quality degradation with fewer steps is graceful rather than catastrophic, with BLEU scores degrading approximately 0.2-0.3 points per 10 fewer steps, allowing practitioners to calibrate the tradeoff precisely for their application.
Limitations and Future Work
While EDDMs address efficiency concerns and offer practical advantages, important limitations and opportunities for improvement remain. Understanding these constraints helps practitioners assess whether EDDMs are appropriate for their specific use cases.
Encoder Dependency: The EDDM architecture's quality ceiling is fundamentally bounded by encoder quality. If the encoder produces poor semantic representations, the decoder— regardless of capacity or denoising steps—cannot recover high-quality output. This creates a critical dependency on the choice and training of the encoder component. While the authors use strong pretrained encoders (RoBERTa-large), this approach may perform suboptimally for specialized domains (legal documents, medical literature, code) where general-purpose encoders lack domain expertise. Future work should explore domain-specific encoders or adapter modules that enable the encoder to specialize to downstream domains without full retraining. Additionally, architectures that enable encoder adaptation during decoder training (rather than freezing the encoder) could provide better quality at the cost of increased training time.
Denoising Latency: While substantially faster than standard diffusion, iterative denoising remains intrinsically slower than single-pass autoregressive generation. Even with optimized schedules, EDDMs require 20-40 forward passes through the decoder network, compared to a single pass for autoregressive models. This fundamental gap limits scenarios with extreme latency constraints (<50ms). While distillation and other acceleration techniques can help, they cannot entirely eliminate this architectural difference. Future work investigating single-step or two-step diffusion variants (using learned acceleration or knowledge distillation) could help close this gap. Hybrid approaches—using autoregressive generation for the first few tokens and diffusion for refinement—represent an interesting middle ground that merits exploration.
Error Accumulation in Long Generation: On open-ended generation tasks requiring very long sequences (>512 tokens), accumulating errors through many denoising steps becomes more problematic. Each denoising step has a small probability of introducing artifacts or breaking semantic coherence. While single passages of 256 tokens show negligible cumulative error, very long documents may exhibit quality degradation. The authors observed ~1 BLEU point drop on 512-token sequences compared to 256-token sequences. For applications requiring multi-page generation (e.g., book writing, academic articles), hierarchical or progressive generation strategies—where subsequences are generated sequentially with intermediate refinement—could address this limitation at the cost of additional latency.
Theoretical Understanding: The interplay between encoder quality, decoder capacity, noise schedule, and overall diffusion efficiency remains not fully understood theoretically. Why do certain encoder architectures pair particularly well with diffusion decoders? How should encoder size relate to decoder size for optimal performance? These questions currently lack principled theoretical answers, forcing practitioners to rely on empirical exploration. Deeper theoretical analysis—potentially drawing from information theory, signal processing, and optimal transport—could provide design principles that guide architecture choices more systematically rather than through trial-and-error.
Conclusion
Encoder-Decoder Diffusion Language Models demonstrate that combining encoder efficiency with diffusion-based generation yields substantial practical improvements in training speed (69% faster), inference efficiency (345% faster), and memory usage (42% reduction) while maintaining competitive generation quality. By leveraging pretrained encoders and optimized diffusion schedules, EDDMs make diffusion-based language generation practical and accessible. As the field continues to explore hybrid generative architectures, encoder-decoder approaches offer a promising path forward for building efficient, high-quality text generation systems.
📄 Original Paper: "Encoder-Decoder Diffusion Language Models for Efficient Training and Inference." arXiv preprint arXiv:2510.22852 (2024). Available at https://arxiv.org/abs/2510.22852