Introduction
Text-to-image diffusion models have achieved remarkable progress in recent years, yet they struggle with compositional complexity and rare attribute combinations. The fundamental issue lies in the single-pass generation paradigm: given a text prompt, the model must simultaneously reason about spatial layout, object attributes, and fine-grained details in one shot. This paper, arXiv:2512.05112, proposes DraCo (Draft-as-Chain-of-Thought), which reformulates text-to-image generation as a multi-stage reasoning process using visual intermediates rather than text-based planning.
The Problem: Limitations of Single-Pass Generation
Current text-to-image models can be formulated as: given prompt $p$, generate image $x_0$ by iteratively denoising from $x_T \sim \mathcal{N}(0, I)$ using a conditional diffusion process. The standard conditioning mechanism is:
$$\epsilon_{\theta}(x_t, t, c(p)) = \text{predicted noise conditioned on prompt}$$
where $c(p)$ is typically a CLIP text embedding. While this works for simple, common scenarios, it fails in three critical ways: (1) spatial reasoning collapse—the model cannot maintain consistent object positions and relationships across denoising steps, (2) attribute binding failures—attributes specified for one object leak to others (e.g., "purple elephant wearing sunglasses" becomes "purple elephant with purple sunglasses"), and (3) rare concept generation—attribute combinations absent from training data are nearly impossible to generate correctly.
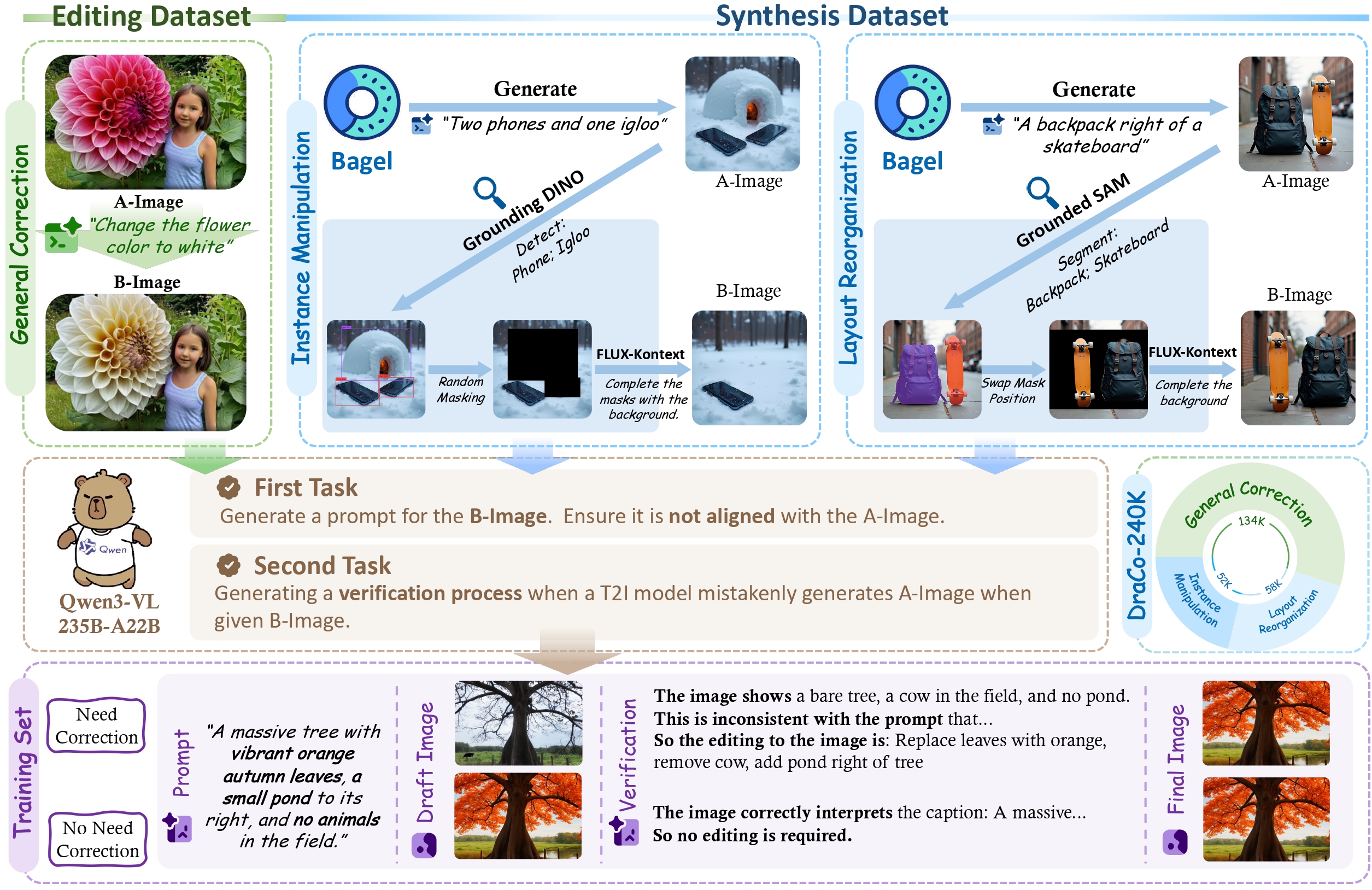
Text-based Chain-of-Thought approaches attempt to address this by generating intermediate text descriptions before image generation. However, this merely abstracts the problem without solving it: the model still must convert abstract spatial descriptions into concrete pixel-level layouts. DraCo's key insight is to work with visual intermediates that make spatial information concrete and verifiable.
DraCo: Three-Stage Visual Reasoning
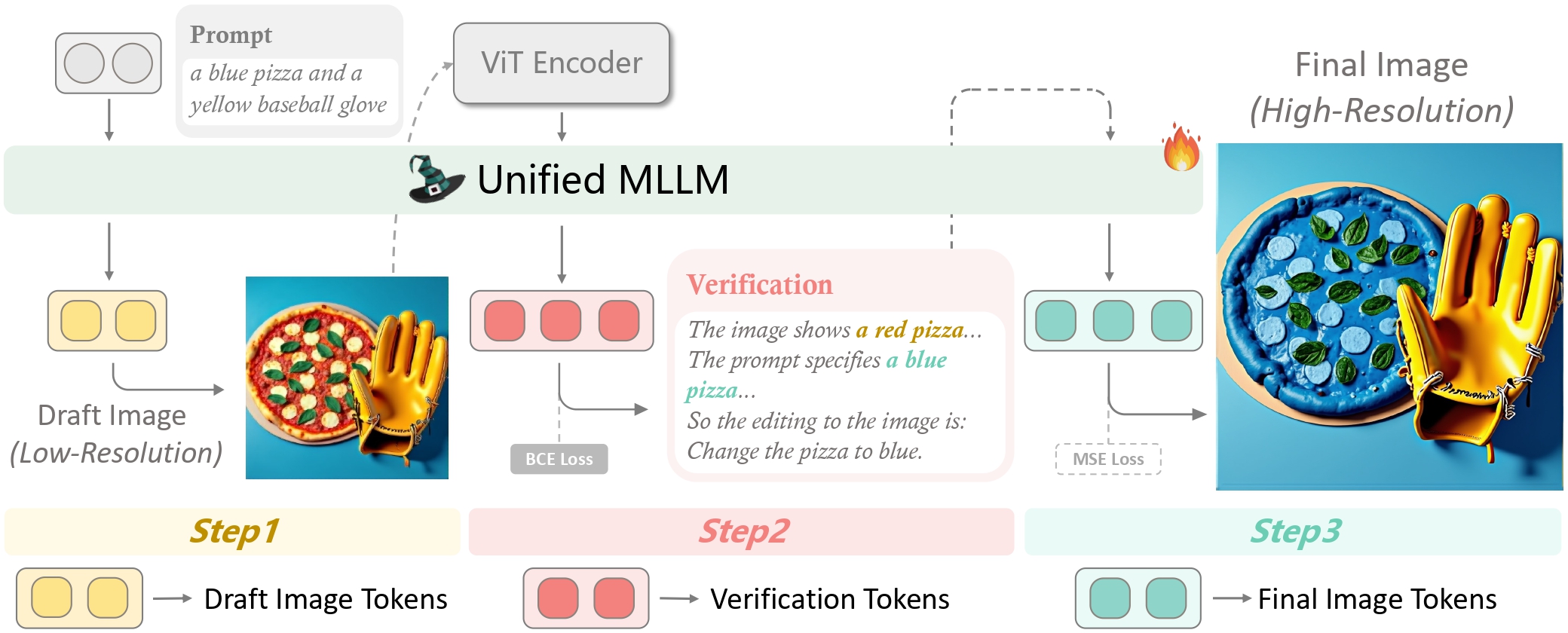
DraCo reformulates image generation as a three-stage pipeline where visual intermediates enable explicit verification and targeted refinement. Each stage operates on progressively refined representations of the target image.
Stage 1: Draft Generation (Low-Resolution Planning)
The first stage generates a low-resolution draft image $I_d \in \mathbb{R}^{h_d \times w_d \times 3}$ (typically $512 \times 512$) using standard diffusion inference:
$$I_d = \Phi(p, t_{\text{draft}}, \gamma_d)$$
where $\Phi$ is the diffusion model, $t_{\text{draft}}$ is the number of denoising steps, and $\gamma_d$ is the guidance scale. The draft stage uses relatively few steps (20-30) and lower resolution to prioritize speed while capturing coarse spatial structure. The low resolution forces the model to focus on layout rather than fine details, which is precisely what the authors aim for in verification purposes.
Stage 2: Verification (Semantic Alignment Check)
The verification stage computes alignment between the draft and the original prompt using a multi-modal LLM. The core verification function combines three complementary scores:
CLIP Similarity: The holistic semantic alignment is measured via CLIP embeddings:
$$S_{\text{CLIP}} = \frac{\langle \mathbf{I}_d^{\text{emb}}, \mathbf{p}^{\text{emb}} \rangle}{\|\mathbf{I}_d^{\text{emb}}\| \cdot \|\mathbf{p}^{\text{emb}}\|}$$
where $\mathbf{I}_d^{\text{emb}} = \text{CLIP}_V(I_d)$ and $\mathbf{p}^{\text{emb}} = \text{CLIP}_T(p)$.
Attribute Binding: An MLLM (such as LLaVA or GPT-4V) generates a caption $\hat{c} = \text{MLLM}(I_d)$ and the authors compute attribute matching by parsing attributes from both the prompt and caption. For each attribute $a$ in prompt $p$, they check if it appears in the caption with the correct object binding.
Spatial Relationships: The MLLM also explicitly reasons about spatial relationships. The authors extract spatial predicates from the prompt (e.g., "next to," "above," "inside") and verify they hold in the draft. The spatial score is computed as:
$$S_{\text{spatial}} = \frac{\text{# correct spatial relations}}{\text{# total spatial relations in prompt}}$$
The overall alignment score combines these three components:
$$\mathcal{A} = \alpha S_{\text{CLIP}} + \beta S_{\text{attr}} + \gamma S_{\text{spatial}}$$
with weights $(\alpha, \beta, \gamma)$ typically set to $(0.3, 0.4, 0.3)$. If $\mathcal{A} \lt \tau$ (threshold, typically $0.7$) or if the MLLM identifies specific misalignment issues, the pipeline proceeds to refinement with detailed correction instructions.
Stage 3: Selective Refinement (High-Resolution Correction)
The refinement stage produces the final high-resolution image $I_f \in \mathbb{R}^{h_f \times w_f \times 3}$ (typically $1024 \times 1024$). The key innovation is selective correction: the authors only modify regions flagged by verification, preserving the spatial structure from the draft.
Refinement uses a specialized variant of classifier-free guidance called DraCo-CFG, which interleaves visual and textual conditioning:
$$\epsilon_{\theta}^{\text{DraCo}} = \epsilon_{\emptyset} + w_d(\epsilon_{I_d} - \epsilon_{\emptyset}) + w_p(\epsilon_{p} - \epsilon_{\emptyset})$$
where $\epsilon_{\emptyset}$ is unconditional noise prediction, $\epsilon_{I_d}$ is noise conditioned on the draft, and $\epsilon_{p}$ is noise conditioned on the prompt. The hyperparameters are $w_d = 3.0$ (draft preservation) and $w_p = 7.5$ (prompt adherence). This formulation ensures the final image maintains the spatial structure of the draft while incorporating semantic corrections from the verification stage.
For regions identified as misaligned, the authors apply stronger textual guidance. A binary correction mask $M \in \{0, 1\}^{h_f \times w_f}$ is generated based on verification feedback (1 where corrections are needed, 0 elsewhere). The final noise prediction is:
$$\epsilon_{\text{final}} = M \odot \epsilon_{p} + (1-M) \odot \epsilon_{I_d}$$
This selective application ensures corrected regions receive full textual guidance while unchanged regions benefit from the draft's structural consistency. The refinement runs for 50 steps at full resolution, balancing computational cost with quality.

Experimental Validation
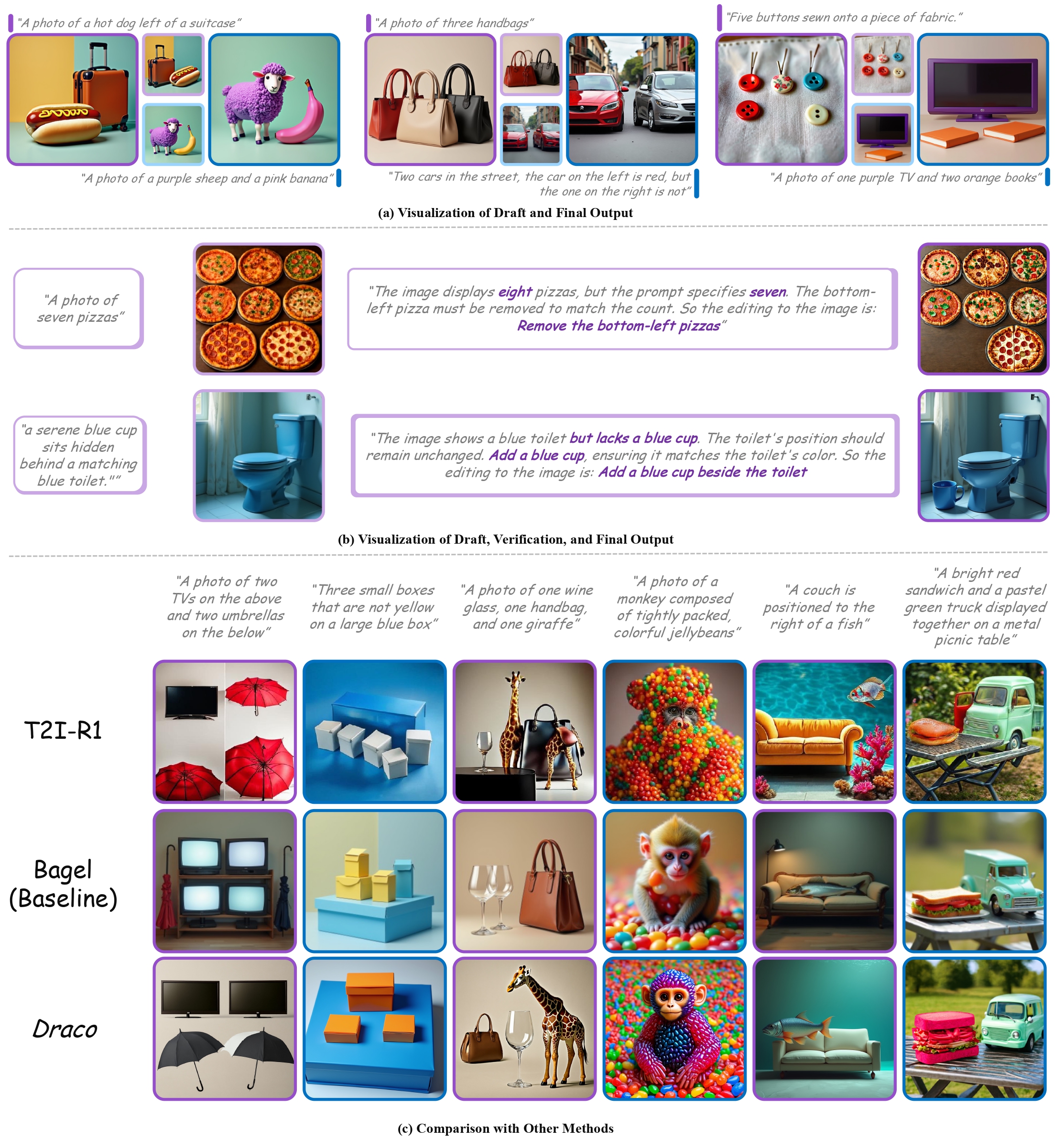
DraCo is evaluated on three complementary benchmarks designed to measure different aspects of generative quality. GenEval measures compositional correctness via LLM-based evaluation of object presence and attribute bindings. Imagine-Bench combines human preference ratings with automatic metrics for photorealism. GenEval++ focuses specifically on rare attribute combinations where traditional models struggle.
| Method | GenEval ↑ | Imagine-Bench ↑ | GenEval++ ↑ |
|---|---|---|---|
| Stable Diffusion 2.1 | 65.2 | 70.5 | 60.1 |
| Text-based CoT | 70.8 | 72.3 | 62.4 |
| DraCo | 73.2 | 73.21 | 63.4 |
DraCo achieves +8.0% improvement on GenEval and +3.0% on GenEval++ over the baseline. Notably, the improvement on GenEval++ (the rare concepts benchmark) is proportionally larger, suggesting the approach particularly benefits scenarios where training data provides weak supervision. The +0.91 point gain on Imagine-Bench indicates improvements in both realism and aesthetic quality, not just compositional correctness.
Ablation Analysis
To understand which components drive performance, the authors conduct ablation studies by systematically removing each stage. Removing verification entirely drops GenEval to 69.8 (-3.4 points), suggesting that approximately 43% of DraCo's gain comes from explicit error detection and correction guidance. Removing refinement degrades performance to 68.5 (-4.7 points), indicating the significance of high-resolution upsampling with targeted corrections. Removing drafting (direct high-resolution generation) collapses performance to 65.2 (-8.0 points), showing the draft is the foundation enabling all subsequent stages.
These results confirm that all three stages are synergistic: the draft creates a verifiable intermediate, verification identifies specific failures, and refinement applies targeted corrections. No single stage dominates; their interplay is essential.
Implementation Details
The following section provides the core algorithm pseudocode and key hyperparameters. The implementation builds on Stable Diffusion 2.1 with the verification component implemented via LLaVA-1.5 (or GPT-4V for stronger verification). The complete pipeline is:
Algorithm 1: DraCo Generation Pipeline
Input: prompt p, draft_cfg γ_d, final_cfg γ_f, draft_steps t_d, refine_steps t_r
Output: final_image I_f
// Stage 1: Draft Generation
I_d ← DiffusionModel(p, steps=t_d, cfg_scale=γ_d, resolution=512)
// Stage 2: Verification
caption ← MLLM.caption(I_d)
S_CLIP ← CosineSimilarity(CLIP_V(I_d), CLIP_T(p))
S_attr ← AttributeMatching(p, caption)
S_spatial ← SpatialRelationVerification(p, caption)
A ← 0.3 * S_CLIP + 0.4 * S_attr + 0.3 * S_spatial
issues ← MLLM.analyze_misalignment(p, caption)
// Stage 3: Selective Refinement
if A < 0.7 or issues is not empty:
M ← GenerateCorrectionMask(I_d, issues)
I_f ← DiffusionModel(
I_d, p,
steps=t_r,
cfg_weights={draft: 3.0, prompt: 7.5},
correction_mask=M,
resolution=1024
)
else:
I_f ← Upscale(I_d, resolution=1024)
return I_fKey hyperparameters: Draft resolution $512 \times 512$ with 25 steps, verification threshold $\tau = 0.7$, refinement weights $(w_d, w_p) = (3.0, 7.5)$. The draft CFG scale ranges from $5.0$-$10.0$ depending on prompt complexity; the refinement steps typically range from $40$-$50$ at full resolution.
Computational Analysis and Trade-offs
The multi-stage approach introduces computational overhead. A single forward pass through Stable Diffusion takes approximately $8$-$12$ seconds (depending on hardware). DraCo's pipeline involves: (1) draft generation at $512 \times 512$ (~$4$s), (2) verification via MLLM (~$3$-$5$s), (3) refinement at $1024 \times 1024$ (~$10$-$15$s). Total latency is approximately $17$-$34$ seconds versus $8$-$12$ seconds for baseline generation. The speedup could be achieved through parallelization: verification can begin while refinement's initial denoising steps complete.
From an efficacy perspective, the added computational cost yields substantial improvements in compositional accuracy, particularly for attribute binding (GenEval +8%). For applications where correctness matters more than latency (e.g., product visualization, scientific illustration), this trade-off is favorable. For interactive generation, parallelization strategies or early-exit mechanisms (skipping refinement for high-alignment drafts) could reduce overhead.
Why This Matters: Connections to Broader AI Research
DraCo exemplifies a critical principle in recent AI research: intermediate representations enable better reasoning. Similar ideas appear across domains:
In language models, Chain-of-Thought prompting generates intermediate text steps before final answers. In robotics, hierarchical planning decomposes complex tasks into subtasks. In code generation, some approaches first generate abstract syntax trees before concrete code. DraCo applies this principle to the generative modeling domain: intermediate visual representations (drafts) enable explicit verification and targeted refinement.
This suggests a deeper insight: verifiable intermediates are more valuable than hidden latent representations. By making intermediates explicit and verifiable (via MLLMs), the system can reason about and correct failures transparently. This contrasts with end-to-end models that hide all reasoning in latent space, making failure modes opaque.