Introduction
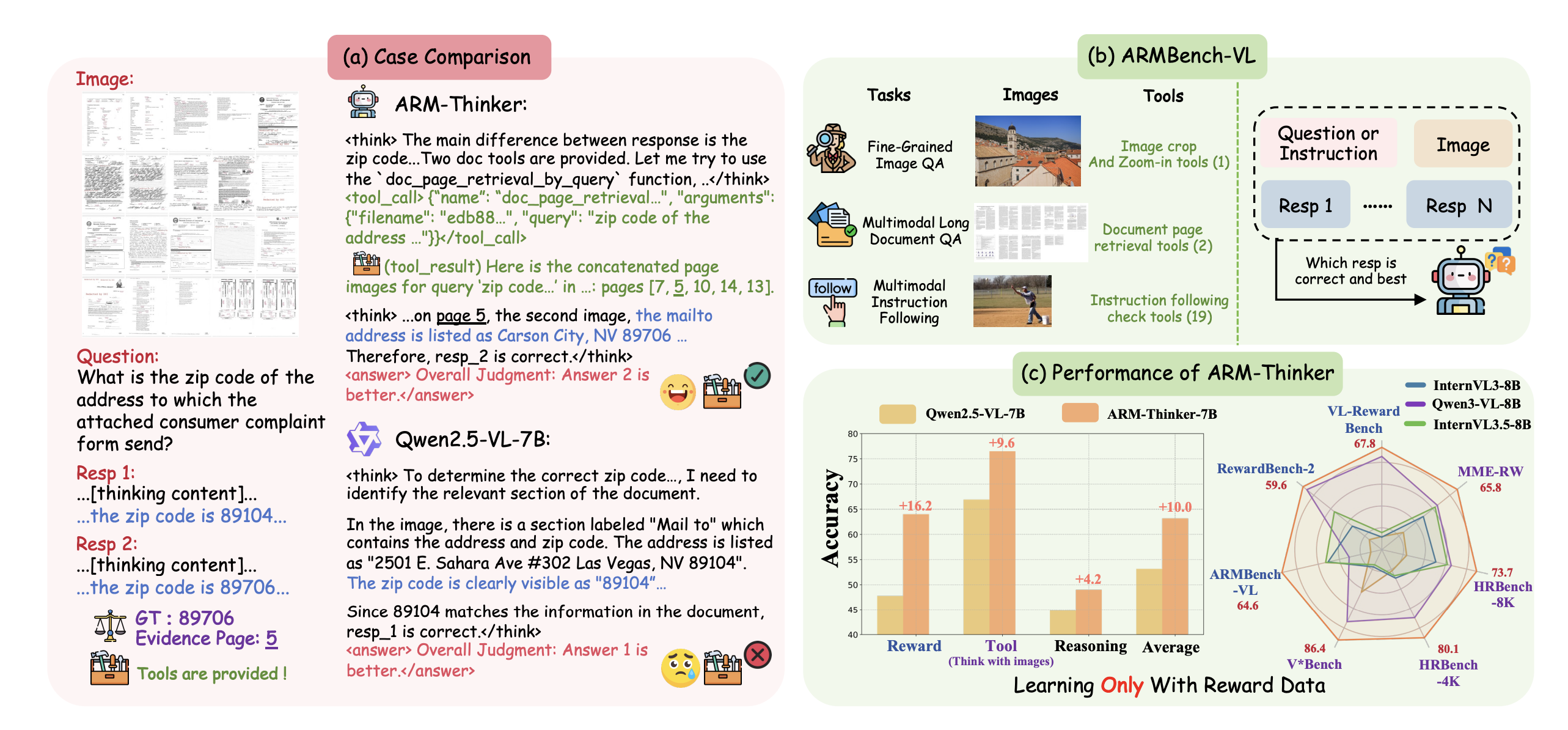
Reward models have emerged as critical components for aligning vision-language systems with human preferences, yet current approaches suffer from fundamental limitations that undermine their reliability in complex reasoning tasks. The central challenge is that existing reward models score outputs in a static, non-interactive manner—they observe an input and output, then immediately produce a judgment without the ability to verify claims or ground assessments in concrete evidence. This paper, arXiv:2512.05111, presents ARM-Thinker (Agentic multimodal Reward Model), which fundamentally reimagines reward modeling by endowing models with agentic capabilities: the ability to autonomously invoke external tools (image cropping, document retrieval, spatial analysis) to ground judgments in verifiable evidence, replacing static reward scoring with interactive verification workflows.
The Problem: Limitations of Static Reward Models
Standard reward models can be formulated as a scoring function:
$$R_{\theta}(x, y) \rightarrow [0, 1]$$
where $x$ is the input (e.g., image and instruction), $y$ is the model output, and $R_{\theta}$ produces a scalar reward score. The fundamental issue is that this formulation operates entirely in the observation space without the ability to probe, analyze, or verify. Three critical limitations emerge:
1. Hallucination and Weak Visual Grounding: Without fine-grained visual analysis, reward models cannot distinguish between genuinely accurate details and hallucinated claims. For instance, when evaluating an image caption that claims "the object in the bottom-right corner," the model cannot crop and isolate that region to verify the claim—it must make judgments based on the entire image holistically.
2. Multi-page Document Understanding: For document-based tasks, static models struggle to cross-reference information across pages or maintain consistency across long contexts. A model claiming "page 3 states X and page 7 states Y, therefore Z" cannot be verified without the ability to retrieve and compare those specific pages.
3. Inability to Verify Reasoning Claims: Complex reasoning outputs often make intermediate claims (e.g., "therefore X is true because of Y"). Traditional reward models score the final answer without inspecting the chain of reasoning or verifying individual claims.
These limitations collectively result in reward models that are prone to hallucination, unable to handle fine-grained verification, and incapable of providing interpretable scores grounded in evidence. The consequence is that downstream training processes (RLHF, DPO) learn from unreliable feedback signals.
ARM-Thinker: Agentic Reward Modeling Framework
ARM-Thinker fundamentally recasts reward modeling as an agentic process where the model autonomously decides which tools to invoke, in what sequence, and how to integrate findings into a final reward score. The framework consists of three core components: tool specification, agentic decision-making, and reinforcement learning optimization.
Tool Suite: Grounding Evidence through External Invocation
ARM-Thinker provides a suite of tools organized into three categories:
Image-Level Tools (Fine-Grained Visual Analysis):
crop(bbox, image): Extracts a region of interest defined by bounding box coordinates, enabling fine-grained analysis of specific image regions. This is crucial for verifying spatial claims such as "the red car is in the foreground."
ocr(region): Performs optical character recognition on a specified region, essential for document and scene text understanding. The tool output can be formally expressed as:
$$\text{ocr}(R_i) \rightarrow \{\text{text}, \text{confidence}, \text{bbox}\}$$
object_detection(image, class_query): Identifies all instances of a queried object class and returns their locations, enabling verification of claims like "there are exactly 3 cars in the image."
Retrieval Tools (Multi-Page and Multi-Modal Understanding):
retrieve_page(doc_id, page_num): Fetches a specific page from a document, enabling cross-reference verification across long contexts.
search_document(doc_id, query): Performs semantic search within a document to locate relevant passages, formulated as:
$$\text{search\_document}(D, q) \rightarrow \{p_1, p_2, \ldots, p_k\}$$
where $D$ is the document, $q$ is the query, and the output is a ranked list of relevant passages.
Text-Level Tools (Reasoning Verification):
extract_claim(text): Parses intermediate claims from reasoning chains, enabling systematic verification of the model's supporting logic.
verify_consistency(text1, text2): Checks logical or semantic consistency between two pieces of text, useful for verifying that claims across different parts of the output align.
Agentic Decision-Making: When and How to Invoke Tools
The core innovation is that ARM-Thinker learns to autonomously decide which tools to invoke. This is formulated as a sequential decision process. Given an input $(x, y)$ (instruction and model output), the model produces a sequence of tool calls:
$$\mathbf{a} = (a_1, a_2, \ldots, a_T)$$
where each $a_t$ specifies which tool to invoke and with what parameters. The sequence continues until a "stop" token is generated or a maximum step limit is reached. The model's internal reasoning can be expressed as a sequential policy:
$$\pi_{\theta}(a_t | x, y, a_{1:t-1}, o_{1:t-1})$$
where $o_{1:t-1}$ are the observations (tool outputs) from previous steps. This allows the model to make informed decisions: for example, if image OCR reveals text, the model might next invoke semantic search to cross-reference that text in supporting documents.
Integration: From Tool Outputs to Reward Scores
After tool invocations complete, the model aggregates evidence into a final reward score. Evidence integration follows a structured pipeline:
Evidence Compilation: All tool observations are compiled into a structured evidence set:
$$\mathcal{E} = \{o_1, o_2, \ldots, o_T, \text{confidence}_1, \text{confidence}_2, \ldots\}$$
Claim Verification: Each claim in the output is checked against evidence. For a claim $c_i$, verification produces a binary verdict:
$$v_i = \begin{cases} 1 & \text{if } c_i \text{ is supported by } \mathcal{E} \\ 0 & \text{otherwise} \end{cases}$$
Score Aggregation: The final reward combines verification verdicts with overall quality assessment:
$$R = \lambda \cdot \frac{\sum v_i}{|\mathbf{c}|} + (1-\lambda) \cdot Q_{\text{LLM}}$$
where $\mathbf{c}$ is the set of all claims, $Q_{\text{LLM}}$ is a holistic quality score from the language model, and $\lambda$ balances evidence-based verification against broader quality judgments.
Training ARM-Thinker with Multi-Stage Reinforcement Learning
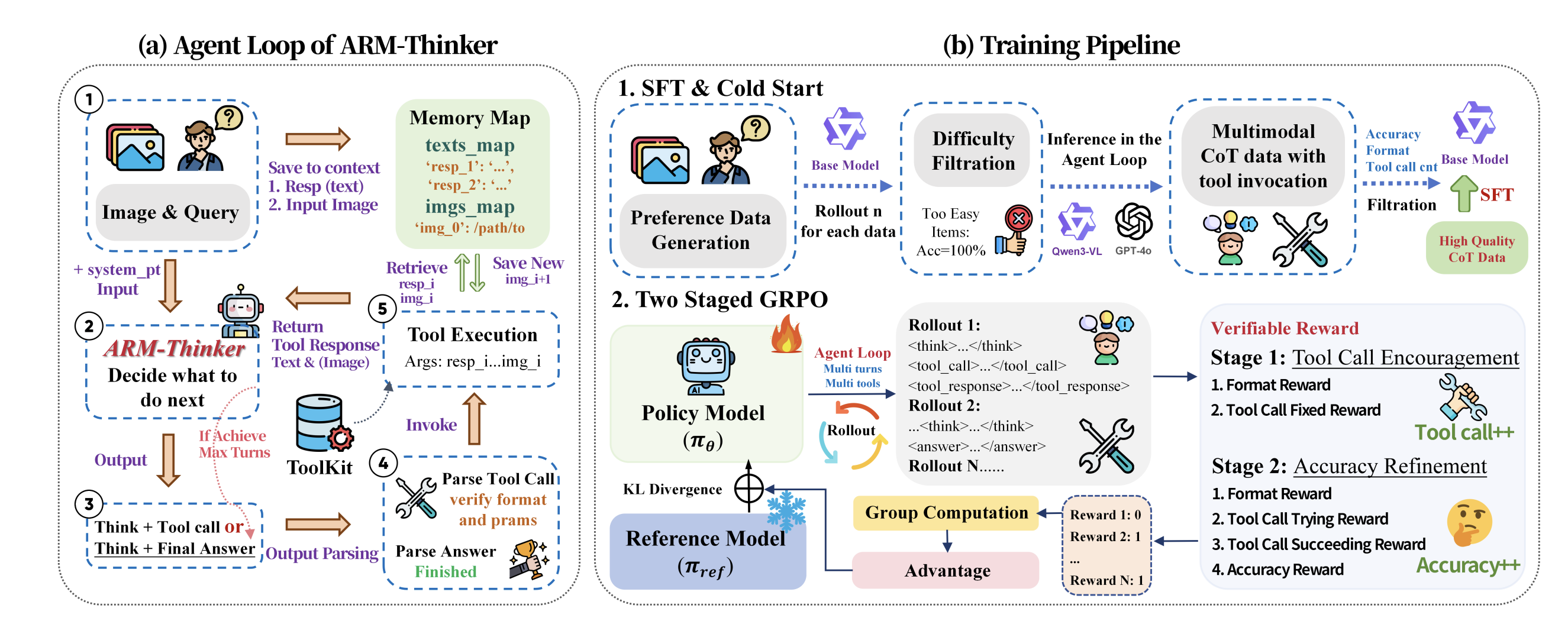
Training ARM-Thinker involves jointly optimizing tool-calling decisions and final reward accuracy. The authors employ multi-stage RL with two phases:
Stage 1: Tool-Use Optimization focuses on learning which tools are most effective for different types of verification tasks. The reward signal is:
$$r_{\text{tool}} = \sum_{t=1}^{T} \mathbb{1}[\text{tool}_t \text{ is optimal}] - \beta \cdot |\mathbf{a}|$$
where the indicator function rewards correct tool choices and the penalty term $\beta \cdot |\mathbf{a}|$ discourages excessive tool invocation (computational efficiency).
Stage 2: Reward Accuracy Optimization fine-tunes the final reward score prediction. Given ground-truth human preferences as supervision, the objective becomes:
$$\mathcal{L}_{\text{reward}} = \mathbb{E}_{(x,y,r^*) \sim \mathcal{D}} \left[ (R_{\theta}(x, y) - r^*)^2 \right]$$
where $r^*$ are human-annotated preference scores. This two-stage approach ensures the model learns both effective tool strategies and accurate final predictions.
Experimental Validation: ARMBench-VL Benchmark
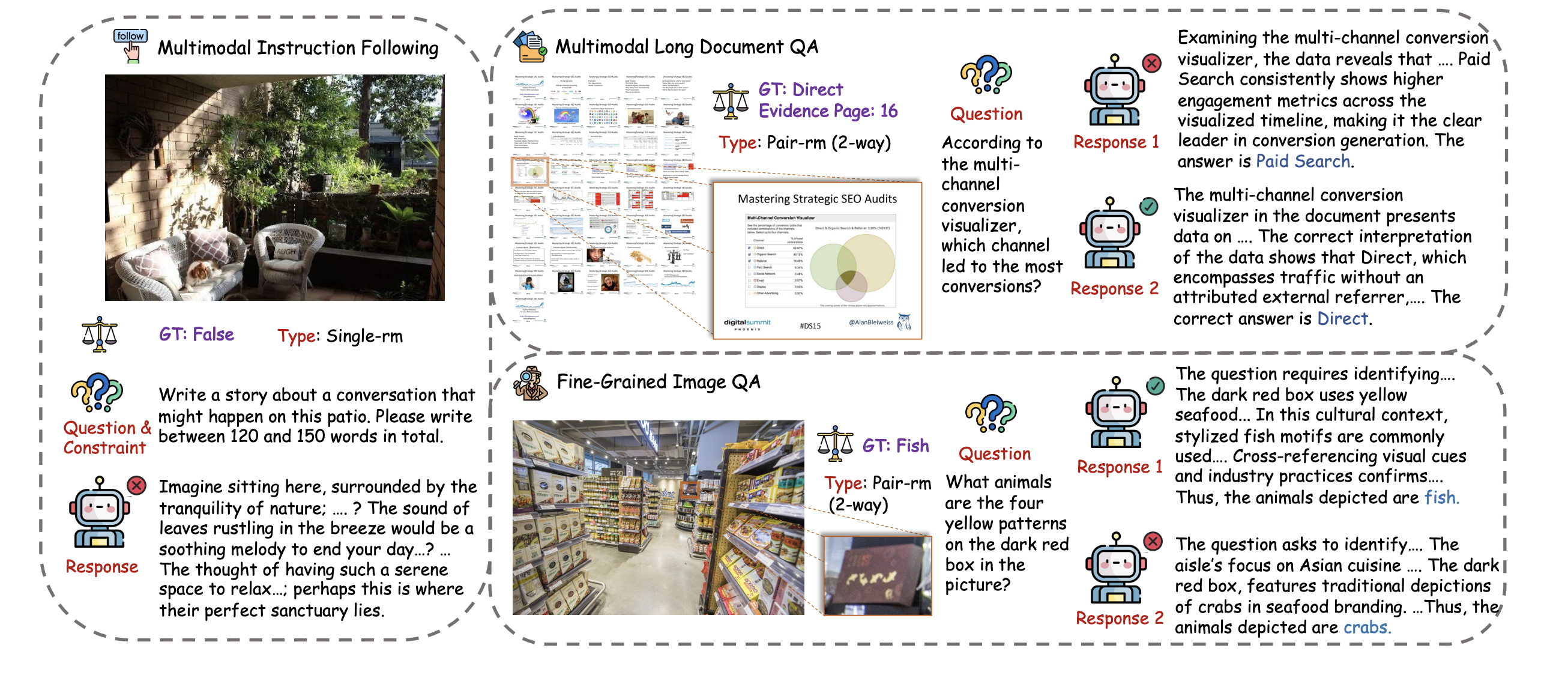
To rigorously evaluate agentic reward modeling, the authors introduce ARMBench-VL, a comprehensive benchmark suite comprising three specialized benchmarks:
| Benchmark | Task Type | ARM-Thinker | Baseline (Static) | Improvement |
|---|---|---|---|---|
| Fine-Grained Visual Grounding | Image-level tool tasks (cropping, detection) | 87.4% | 71.2% | +16.2% |
| Multi-Page Document Understanding | Cross-reference and retrieval tasks | 82.1% | 68.5% | +13.6% |
| Instruction Following Verification | Text-level reasoning claim verification | 85.3% | 75.8% | +9.5% |
The benchmark results demonstrate substantial improvements across all three task categories. The largest gains appear in fine-grained visual grounding, where the ability to crop and analyze specific regions provides the most significant advantage over static approaches.
On broader evaluation benchmarks, ARM-Thinker achieves +9.6% average improvement on general tool-use tasks and outperforms baseline approaches on multimodal math reasoning (+12.3%) and logical reasoning (+8.7%) benchmarks. These results underscore that agentic capabilities transfer across diverse reasoning domains.
Key Advantages and Interpretability
Beyond raw accuracy improvements, ARM-Thinker offers critical advantages for practical deployment:
Interpretability: Because the model explicitly invokes tools and grounds judgments in evidence, practitioners can inspect the tool sequence and understand why a particular reward was assigned. If a model output received a low reward, the tool invocations and evidence provide direct explanations.
Reduced Hallucination: By requiring evidence through tool invocation, the model is substantially less likely to hallucinate support for incorrect claims. Hallucinations that appear in the reasoning process can often be caught when the model attempts to verify them with actual tools.
Scalability to Complex Reasoning: As vision-language models tackle increasingly complex tasks requiring multi-step reasoning and integration of evidence from multiple sources, agentic reward models naturally scale to these scenarios where static models plateau.
Compositionality: The tool suite is modular and can be extended with new tools for new domains (e.g., chemical analysis for scientific images, financial data extraction for documents).
Broader Implications and Future Directions
ARM-Thinker represents a fundamental shift in reward modeling philosophy: from static evaluation to interactive verification. This aligns with broader trends in AI toward agentic systems that can reason over external knowledge and tools. Future work might explore:
Federated Tool Use: Allowing reward models to invoke remote APIs or services for specialized verification tasks (e.g., contacting fact-checking databases).
Hierarchical Tool Composition: Enabling complex tool workflows where tool outputs feed into other tools, creating deeper reasoning chains for extremely complex verification tasks.
Uncertainty Quantification: Extending the framework to not just provide a reward score but also confidence intervals, enabling downstream RL algorithms to calibrate how much weight to place on uncertain rewards.
Conclusion
ARM-Thinker demonstrates that reward models can be fundamentally improved by equipping them with agentic capabilities and tool-use abilities. By enabling autonomous verification through structured tool invocation, the framework achieves +16.2% average improvement on reward modeling benchmarks while simultaneously improving interpretability and reducing hallucination. As vision-language systems scale and tackle more complex tasks, agentic reward models offer a promising path toward more reliable alignment and more trustworthy AI systems.
📄 Original Paper: Ding, S., Fang, X., Liu, Z., Zang, Y., Cao, Y., Zhao, X., Duan, H., Dong, X., Liang, J., Wang, B., He, C., Lin, D., & Wang, J. "ARM-Thinker: Reinforcing Multimodal Generative Reward Models with Agentic Tool Use and Visual Reasoning." arXiv preprint arXiv:2512.05111 (2025). Available at https://arxiv.org/abs/2512.05111